Warning this is a long blog! Full details of this will be available in next week’s release of Microservice Deployment, from VirtualPairProgrammers!
This week I have been mainly getting Eureka into production. Specifically, I’m deploying to AWS, in a multi availability-zone configuration. I have an Auto Scaling Group firing up two instances, each in a different Availability Zone (AZ).
This has been, to put it mildly, an “interesting challenge”. Obviously Netflix have a massive production load running on it – so we know it works! – but the documentation on how the rest of us should configure it is sketchy at the time of writing.
This blog concentrates on a problem which will be fixed in the forthcoming “Dalston” releases of Spring Cloud, but it may affect those on legacy code bases. (Also Dalston is due for release later in February and I can’t delay the course any longer!) [Edit April 2018 – according to the GitHub Issue that reported this, the bug is still open in the Edgware release train, so this blog post is still relevant].
Note: much of this has been done in a limited timescale under pressure. Ideally when the pressure is off I would spend time examining more of the source code – and I will have misinterpreted or plain got stuff wrong, so do comment or contact me if you know more than me!
Problem: Zombie Instances.
The main problem I’ve had in preparing the architecture is zombies. Any instance which has been forcibly terminated is not expired from Eureka and remains, indefinitely, as a “Zombie” instance. This is catastrophic because these Zombie instances will continue to be called by clients, even when healthy versions of the instances exist. (We are using Hystrix which can be a hindrance if the fallback hides the problem – I’ve switched off all Circuit Breakers for this exercise).
(nb If an instance closes cleanly, this isn’t a problem because the instance deregisters itself from Eureka and this is fine.)

The instance highlighted above was killed about an hour ago…..

And here’s the live and dead (stopped) instance in the AWS EC2 Console.
Even though the instance is long dead, clients will still be handed both the live and dead instance references. As we’re using Ribbon as a load balancer on the client side, about half the time we get….
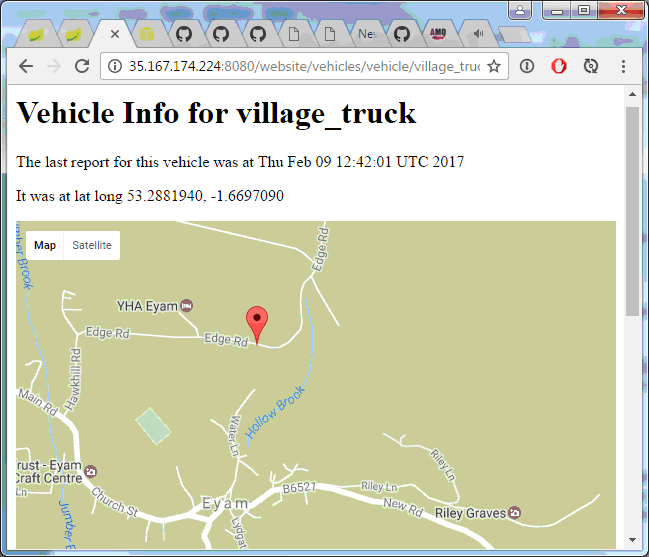
Hooray! But half the time we get….

Boo! Recall that I’ve temporarily disabled circuit breakers, so no fallbacks are available, making the crash more obvious.
Possible Solutions:
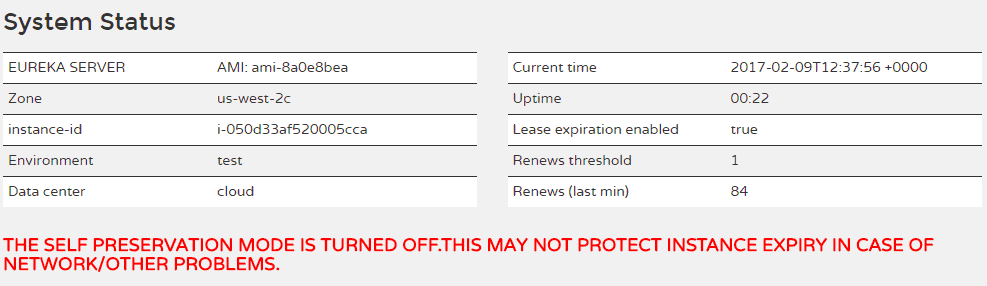
Self Preservation Mode.
I won’t bother re-describing self preservation mode here as the references 2) and 3) cover this well.
In development where you only have a handful of instances, this mode is a right pain in the neck because a single instance deregistering is interpreted as a network catastrophe, and Eureka stops de-registering instances, on the (for us, bad) assumption that the instance is still there, it’s just that Eureka can’t see it for some reason. So it will continue serving details of this instance to clients.
For me, I don’t think this was the problem. I had other instances registered which stopped the threshold kicking in – *I think*. Just to be sure, I decided to drop the threshold right down (I never saw the red emergency warning so I assume self preservation wasn’t happening). In desperation, I decided to switch this mode off altogether – you get a red angry warning for doing this, but who cares?
The follow properties achieve this:
# Make the number of renewals required to prevent an emergency tiny (probably 0)
eureka.server.renewalPercentThreshold=0.1
# In any case, switch off this annoying feature (for development anyway).
eureka.server.enableSelfPreservation=false
Q: Is the self preservation feature really all that useful? Obviously Netflix thinks so and I believe them. But I’d like to get a handle on what the use is. In the event of a network partition, causing Euerka to expire all of the instances, won’t the clients continue using their own cached instances anyway? The “emergency” doesn’t sound that serious to me, and certainly no worse than clients getting references to zombie instances. I need to investigate this more deeply when the pressure is off.
2) EIP binding causes incorrect metadata – bounce the server.
This was the real reason.
Eureka instances need a fixed IP address or domain name. Usually you would achieve this by setting up a Load Balancer (which in AWS is given a fixed domain name – it’s ip address may vary over time but you are insulated from that). Then you could place the Eureka instances behind the load balancer.
However, Eureka has its own scheme, as described in reference 5).
1) Reserve yourself a set of Elastic IP (EIPs) addresses from AWS, one for each of your Eureka instances (I need two). This gives you an IP address permanently allocated to your account, and we can freely associate them with any of our EC2 instances.
2) Configure your Eureka Server with a comma separated list of all of the EIPs. Eureka insists that you use the full DNS style name:
eureka.client.serviceUrl.defaultZone=http://ec2-35-166-222-19.us-west-2.compute.amazonaws.com:8010/eureka/,http://ec2-35-167-126-96.us-west-2.compute.amazonaws.com:8010/eureka/
Typically, you’d bake the Eureka code base onto an AMI so that you can start up new Eurekas easily from an Auto Scaling Group.
3) Start up an EC2 instance, from the AMI containing your Eureka image. It’s IP will, as usual, be dynamically allocated by AWS, so it will be something like 55.34.23.123 (whatever).
4) Now for the weird bit….as part of the startup process, Eureka will grab one of the EIPs from the list given in step 2), and it will re-bind the IP address of this EC2 instance to that EIP. That’s right, the IP address of this server will be changed, on the fly, during the startup of the instance.
5) The other instance will do the same thing – but in this case it will find that the first address in the list has already been taken, so it then tries the second item in the list. It will successfully bind to this IP address.
And, hey presto you now have two Eurekas, peers of each other, each having the correct IP addresses that we knew about in advance.
For the clients, we can give them the exact same config (this is convenient because we can put this property in the global config server instead of having to repeat it in every single microservice):
eureka.client.serviceUrl.defaultZone=http://ec2-35-166-222-19.us-west-2.compute.amazonaws.com:8010/eureka/,http://ec2-35-167-126-96.us-west-2.compute.amazonaws.com:8010/eureka/
The client can now choose either of these URLs to work with as its Eureka server. According to the docs (although I haven’t had time to verify this), the client will favour a Eureka server in it’s own availability Zone – this is presumably for optimal performance. However this isn’t critical, if that server isn’t available it will fall over to another one from the list, ie from a different AZ. This will incur slower performance, although the AZs have low latency connections with other AZs in the same region.
(Note that the Eureka replicas aren’t a master/slave arrangement, its peer-peer so there’s no “main” Eureka server. For a client in AZ us-west-2b, their preferred server is in that zone but it’s just a preference).
So that’s how Eureka is designed to bootstrap itself, but it seems this is the root of the Zombie problem.
Here’s my server, which after booting up grabbed itself the EIP 35.167.126.96:

But check out the instance info at the bottom:
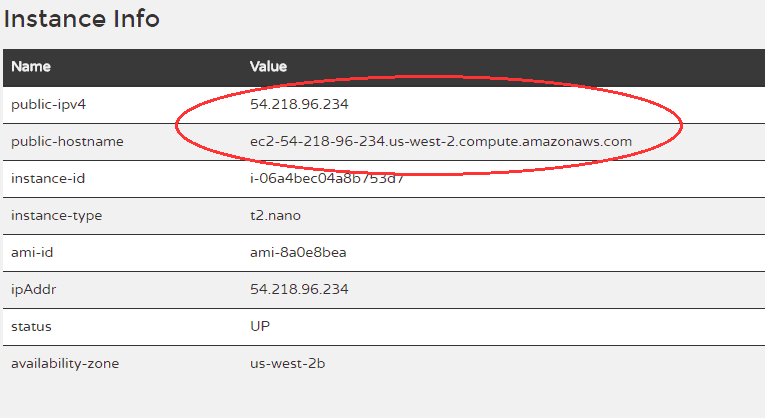
The public-ipv4 and public-hostname are wrong – these were correct when the instance was booting up, but after the EIP bind, these values are now redundant.
So what? Well, I’m not sure. The public hostname is important to Eureka, and I can see how it would prevent the servers from replicating with each other – because Eureka uses the hosts names to find its replicas:

This Eureka instance thinks its peers are unavailable, because it’s looking for host names containing the 35-xxx-xxx-xx series of numbers. But as shown above, the hostnames are stuck on the “old values of “54-xxx.xxx-xxx”.
Confusion: I would understand if this stopped replication working – actually replication is working fine despite the UI above indicating unavailable replicas.
Now, I do not understand why (again, I need to take time to step through source code), but what is demonstrably true is that this misconfiguration causes the zombie instances. Maybe someone out there can explain this.
A quick fix for the problem is to simply log on to the Eureka instances and restart the spring boot application. This will causes their instance data to be refreshed, this time to the correct values:

The instance info after a restart of the Eureka App – as an EIP bind wasn’t necessary this time, the IP address hasn’t changed and the values populated on startup are now correct.

And the replication is now correct – we can see the “other” Eureka instance listed as available.
But the real difference (at last, I get to the point!!!) is that instance de-registration is now working. Let’s start up two instances of the microservice:

Above: two instances running in EC2

Above: correctly registered in Eureka….
Now I’m going to kill a random instance and start a stopwatch:

This time, success! After 2mins42s (more on the timings later) I saw the cancellation run through the server log:

Which is confirmed on the UI:
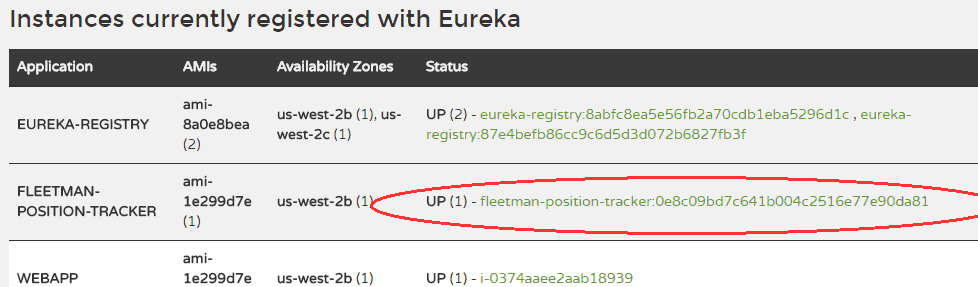
Note that this does not mean that the clients will now have clean, non-zombie references. Eureka actually sends a Json document back to clients which it caches (I think for 30seconds), so it may take up to 30 seconds before the zombie disappears from data sent to clients. And then, Ribbon on the client side has a cache as well. So many caches and often I’ve banged my head thinking everything is unreliable when actually it just takes times for the caches to align.
A minute later and every refresh on my webpage is showing a map again. Joy.
So, I cannot explain why the bad instance information is preventing Zombie expiration, but it does. Any ideas???
Refreshing the Instance Info Automatically
Trouble is, we can’t rely on being able to “bounce” the Eureka app every time it starts up. I did consider adding additional steps to my Ansible script; I could:
– fire up Eureka from AMI
– Wait for port 8010 to respond on the EIP
– Restart Eureka App
But that wouldn’t work for when the server is started from an Auto Scaling Group – and that’s a requirement, if Eureka EC2 instance terminates for any reason, it needs to be auto started again. The ASG will just restore the AMI which will cause an EIP bind to happen, but unless we do something clever (a script that triggers after an ASG event? My head’s hurting) the instance information will be in that bad state.
So, thanks to the GitHub issue at reference 1) (EIP publicip association not correctly updated on fresh instance), Niklas Herder (to whom I owe a drink, or something) suggested using a timer in the main class of the Eureka App to automatically refresh the instance’s info if that info has changed. It works perfectly.
I’ve modified his suggested code slightly to remove anything we don’t need, and I’m left with this….
@Bean
public EurekaInstanceConfigBean eurekaInstanceConfigBean(InetUtils utils) {
final EurekaInstanceConfigBean instance = new EurekaInstanceConfigBean(utils)
{
@Scheduled(initialDelay = 30000L, fixedRate = 30000L)
public void refreshInfo() {
AmazonInfo newInfo = AmazonInfo.Builder.newBuilder().autoBuild("eureka");
if (!this.getDataCenterInfo().equals(newInfo)) {
((AmazonInfo) this.getDataCenterInfo()).setMetadata(newInfo.getMetadata());
this.setHostname(newInfo.get(AmazonInfo.MetaDataKey.publicHostname));
this.setIpAddress(newInfo.get(AmazonInfo.MetaDataKey.publicIpv4));
this.setDataCenterInfo(newInfo);
this.setNonSecurePort(8010);
}
}
};
AmazonInfo info = AmazonInfo.Builder.newBuilder().autoBuild("eureka");
instance.setHostname(info.get(AmazonInfo.MetaDataKey.publicHostname));
instance.setIpAddress(info.get(AmazonInfo.MetaDataKey.publicIpv4));
instance.setDataCenterInfo(info);
instance.setNonSecurePort(8010);
return instance;
}
It’s a hack, sure, but it works! Forgive the hardcode of the 8010, I haven’t got around to polishing this off yet.
Just to prove it, I’ll run through the exercise again:

After baking the new “refresh” code into an AMI, I’ve started an Auto Scale Group which has triggered the startup of two new Eureka Servers. Notice their IPs are in the 54.xx.xx.xx range.
… a few minutes later and their IPs have changed:

The all important instance info is up to date:

And all is well with the world. This time I killed an instance and after 2mins 57seconds the registration was cancelled.
This problem will be fixed when the Spring Eureka migrates to the underlying Eureka implementation version 1.6. The Dalton release train will be the first release containing the fix. We’re still on Camden and for “reasons” I want to stay with that for now (mainly, I don’t want to delay and I don’t want to change what we have). But all of the above may not be an issue for you.
In the next blog post, I’ll address the other pain in the neck with Eureka, which is slow registration and de-registration.
I’m indebted to the following resources
-
- github.com/spring-cloud/spring-cloud-netflix/issues/373 – Bertrand Renuart has described many of the internals excellently – this would form a good basis for an improved set of official documents.
-
- At the time of writing, Abhijit Sarkar is clearly going through similar pain as me and he’s writing up an excellent blog “Spring Cloud Netflix Eureka – The Hidden Manual”. blog.abhijitsarkar.org/technical/netflix-eureka/. This seems to be a work in progress, I hope his work will become the actual manual before long.
-
- The Spring Cloud Eureka documentation has a few references to production settings.
-
- This is the only guide I know of to EIP binding, although the settings given here don’t seem to work properly in Spring Cloud Eureka.
There is also the Netflix Wiki at https://github.com/Netflix/eureka/wiki which is a reasonable start, but many of the details are vague and confusing. Some details are not relevant to the Spring Cloud version of Eureka. The document starts by advising to create multiple properties for each AZ; I’ve failed to get Spring to pick this up and in all examples I’ve only seen a list of addresses (comma separated) on the eureka.client.serviceUrl.defaultZone property. I’ve gone with that and it seems ok but I’m interested to find out more.